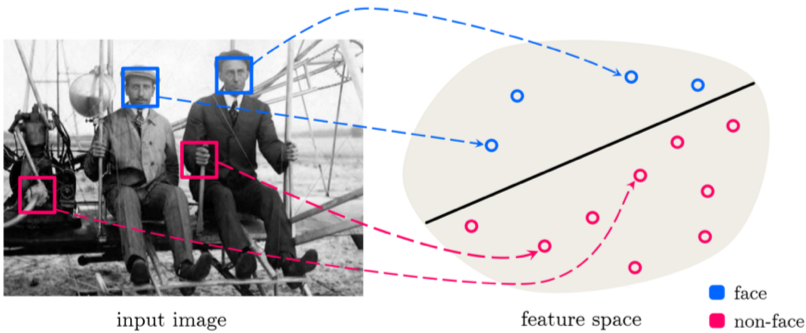
Reinforcement Learning (RL) is a general machine learning framework for building computational agents which can, if trained properly, act intelligently in a complex (and often dynamic) environment in order to reach a narrowly-defined goal. Interesting applications of this framework include game AI (e.g., AlphaGo, chess, self-playing Atari and Nintendo games) as well as various challenging problems in automatic control and robotics.
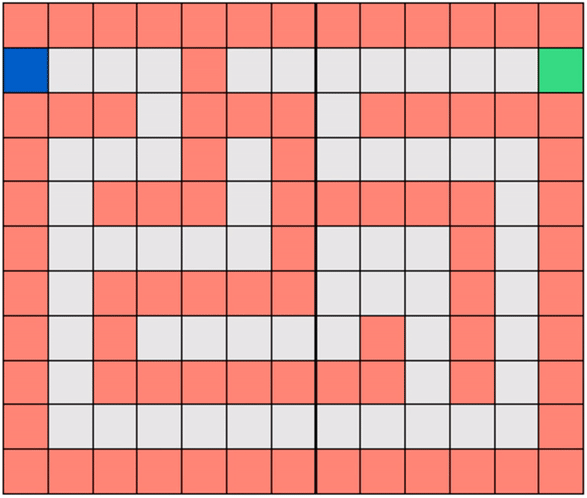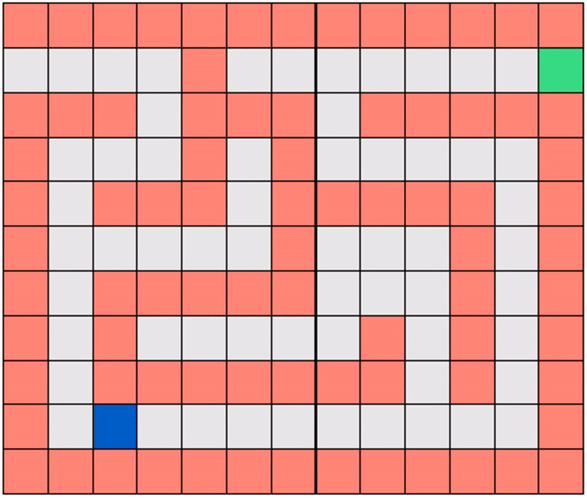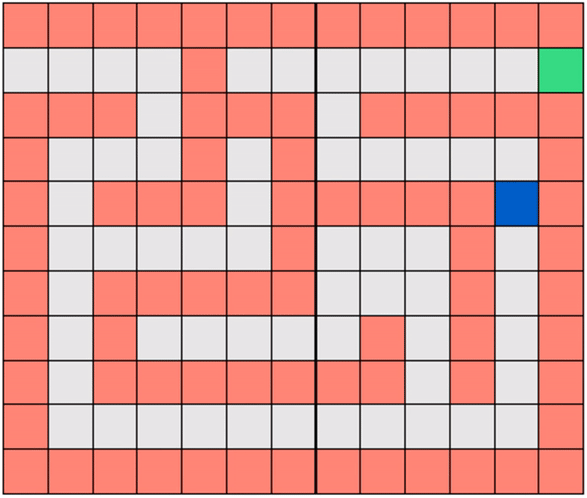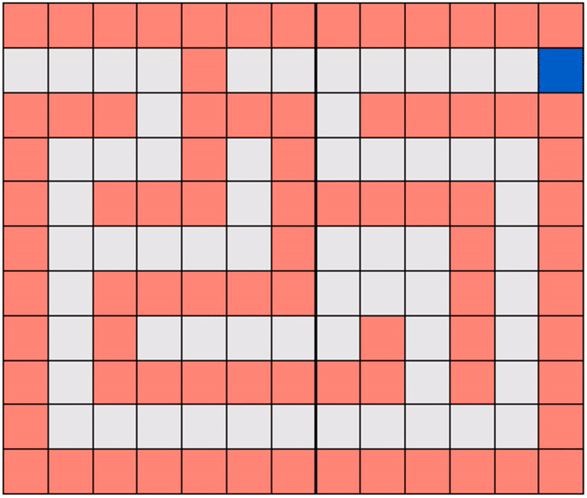
In this post we introduce the fundamentals of Reinforcement Learning, its nomenclature, and problem types including the Gridworld environment shown below where the agent/robot is trained to solve a maze.In this notebook we derive the most basic version of the so-called Q-Learning algorithm for training Reinforcement agents. We use our Gridworld environment to help illustrate how Q-Learning works in practice.

Previously in part 2 of the Reinforcement Learning series, we introduced the basic Q-Learning algorithm as a means to approximate the fundamental Q function associated to every RL problem. In this post we continue our discussion, and introduce two simple yet powerful enhancements to the basic Q-Learning algorithm.
The animation below shows how one of these enhancements, based on the exploration-exploitation trade-off, increases the training efficiency of our Gridworld agent.