Linear Supervised Learning Series¶
Part 1: Linear regression¶
In this post we formally describe the problem of linear regression, or the fitting of a representative line (or hyperplane in higher dimensions) to a set of input/output data points.
Regression in general may be performed for a variety of reasons: to produce a so-called trend line (or - more generally - a curve) that can be used to help visually summarize, drive home a particular point about the data under study, or to learn a model so that precise predictions can be made regarding output values in the future.
Press the button 'Toggle code' below to toggle code on and off for entire this presentation.
from IPython.display import display
from IPython.display import HTML
import IPython.core.display as di # Example: di.display_html('<h3>%s:</h3>' % str, raw=True)
# This line will hide code by default when the notebook is eåxported as HTML
di.display_html('<script>jQuery(function() {if (jQuery("body.notebook_app").length == 0) { jQuery(".input_area").toggle(); jQuery(".prompt").toggle();}});</script>', raw=True)
# This line will add a button to toggle visibility of code blocks, for use with the HTML export version
di.display_html('''<button onclick="jQuery('.input_area').toggle(); jQuery('.prompt').toggle();">Toggle code</button>''', raw=True)
1. Linear regression¶
With linear regression we aim to fit a line (or hyperplane in higher dimensions) to a scattering of data. In this Section we describe the fundamental concepts underlying this procedure.
1.1 Notation and modeling¶
Data for regression problems comes in the form of a set of $P$ input/output observation pairs
\begin{equation} \left(\mathbf{x}_{1},y_{1}\right),\,\left(\mathbf{x}_{2},y_{2}\right),\,...,\,\left(\mathbf{x}_{P},y_{P}\right) \end{equation}or $\left\{ \left(\mathbf{x}_{p},y_{p}\right)\right\} _{p=1}^{P}$ for short, where $\mathbf{x}_{p}$ and $y_{p}$ denote the $p^{\textrm{th}}$ input and output respectively.
In simple instances the input is scalar-valued (the output will always be considered scalar-valued here)
Hence the linear regression problem is geometrically speaking one of fitting a line to the associated scatter of data points in 2-dimensional space.
In general however each input $\mathbf{x}_{p}$ may be a column vector of length $N$
\begin{equation} \mathbf{x}_{p}=\left[\begin{array}{c} x_{1,p}\\ x_{2,p}\\ \vdots\\ x_{N,p} \end{array}\right] \end{equation}in which case the linear regression problem is analogously one of fitting a hyperplane to a scatter of points in $N+1$ dimensional space.
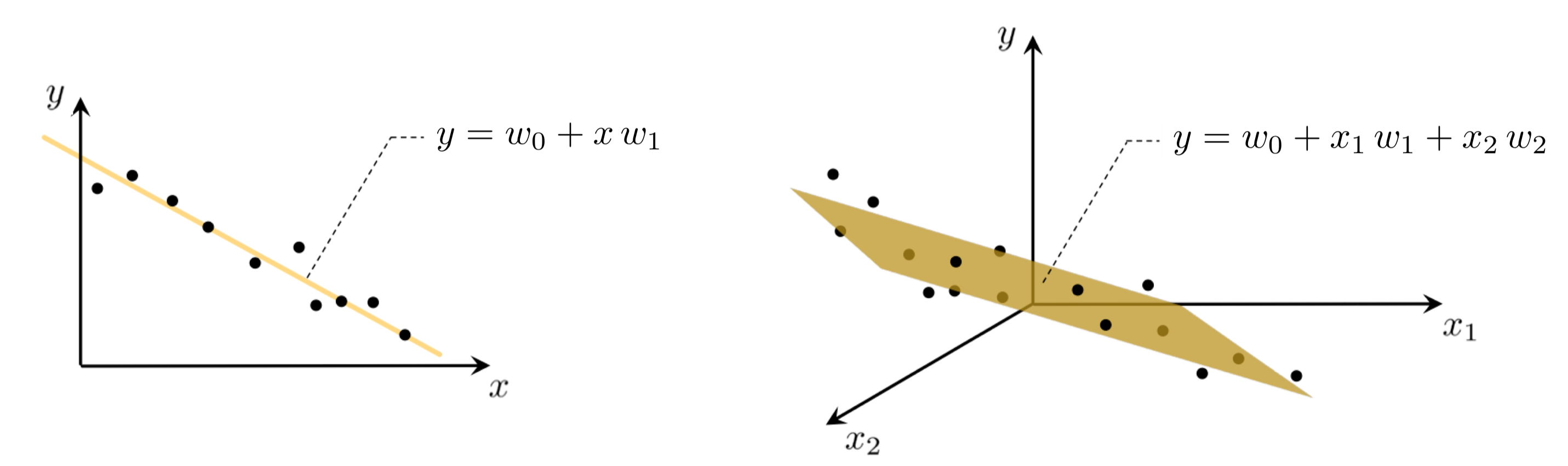
In the case of scalar input we fit a line to the data requiring we determine a vertical intercept $w_0$ and slope $w_1$ so ideally that
\begin{equation} w_{0}+x_{p}w_{1}\approx y_{p},\quad p=1,...,P. \end{equation}More generally, when dealing with $N$ dimensional input we have a bias and $N$ associated slope weights to tune properly in order to fit a hyperplane so ideally
\begin{equation} w_{0}+ x_{1,p}w_{1} + x_{2,p}w_{2} + \cdots + x_{N,p}w_{N} \approx y_{p} ,\quad p=1,...,P. \end{equation}For any $N$ we can write the general case more compactly denoting
as
\begin{equation} w_0+\mathbf{x}_{p}^T\mathbf{w} \approx y_{p} ,\quad p=1,...,P. \end{equation}1.2 The Least Squares cost function¶
To find the parameters of the hyperplane which best fits a regression dataset, it is common practice to first form the Least Squares cost function.
For a given set of parameters $\mathbf{w}$ this cost function computes the total squared error between the associated hyperplane and the data (as illustrated pictorially in the Figure below).
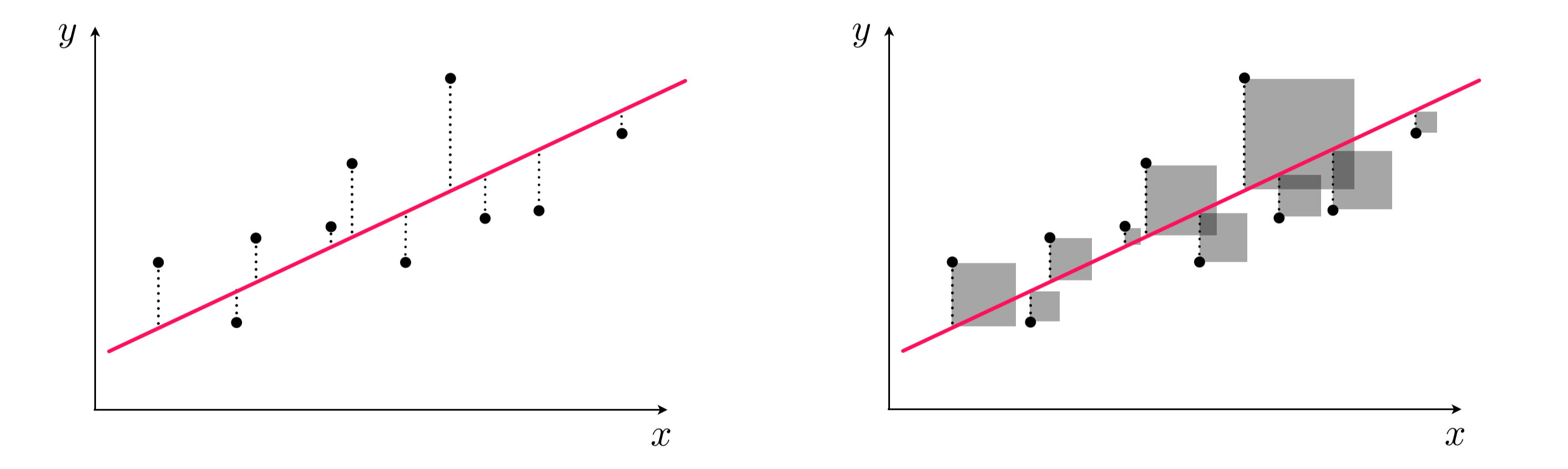
Naturally then the best fitting hyperplane is the one whose parameters minimize this error.
We want to find a weight vector $\mathbf{w}$ and the bias $w_0$ so that each of $P$ approximate equalities
\begin{equation} w_0+\mathbf{x}_{p}^T\mathbf{w} \approx y_{p} \end{equation}holds as well as possible.
Another way of stating the above is to say that the error between $w_0+\mathbf{x}_{p}^{T}\mathbf{w}$ and $y_{p}$ is small. One natural way to measure error between two quantities like this is simply to square their difference as
\begin{equation} \left(w_0+\mathbf{x}_{p}^{T}\mathbf{w} - y_{p}^{\,}\right)^2 \end{equation}Since we want all $P$ such values to be small we can sum them up - forming the Least Squares cost function for linear regression
\begin{equation} \,g\left(w_0,\mathbf{w}\right)=\sum_{p=1}^{P}\left(w_0+\mathbf{x}_{p}^{T}\mathbf{w}-y_{p}^{\,}\right)^{2} \end{equation}We want to determine a value for the pair $w_0$ and $\mathbf{w}$ that minimizes $g\left(w_0,\mathbf{w}\right)$, or written formally we want to solve the unconstrained problem
\begin{equation} \underset{w_0,\,\mathbf{w}}{\mbox{minimize}}\,\,\underset{p=1}{\overset{P}{\sum}}\left(w_0+\mathbf{x}_{p}^{T}\mathbf{w}-y_{p}^{\,}\right)^{2} \end{equation}1.3 Minimization of the Least Squares cost function¶
As discussed in our mathematical optimization series, generally speaking determining the overall shape of a function - i.e., whether or not a function is convex - helps determine the appropriate optimization method(s) we can apply to efficiently determine the ideal parameters.
In the case of the Least Squares cost function for linear regression it is easy to check that the cost function is always convex regardless of the dataset.
Example 2: Visually verifying the convexity of the cost function for a toy dataset¶
In this example we plot the contour and surface plot for the Least Squares cost function for linear regression for a toy dataset.
# load in dataset
datapath = '../../mlrefined_datasets/superlearn_datasets/2d_linregress_data.csv'
data = np.asarray(pd.read_csv(datapath,header = None))
# create instance of linear regression demo, used below and in the next examples
demo1 = superlearn.lin_regression_demos.Visualizer(data)
# plot dataset
demo1.plot_data()

The contour plot and corresponding surface generated by the Least Squares cost function using this data are shown below.
# demo.center_data()
demo1.plot_ls_cost(view = [30,80],viewmax = 4,num_contours = 30)

- the elliptical contours and 'upward bending' shape of the surface indeed confirms the function's convexity
The Least Squares cost function for linear regression is always convex regardless of the input dataset, hence we can easily apply either gradient descent or Newton's method in order to minimize it.
Example 3: Using gradient descent to minimize the Least Squares cost on our toy dataset¶
The simplest way to code up gradient descent in the same manner as shown above is to simply take the generic unnormalized gradient descent Python code provided in Part 2 of our series on mathematical optimization, and simply plug in the Least Squares cost function.
Here the automatic differentiator autograd is used to efficiently compute the gradient at each step. One can implement the cost function in Python as shown in the next Python cell.
# an implementation of the least squares cost function for linear regression for N = 2 input dimension datasets
x = data[:,0] # define input of dataset prior to function definition
y = data[:,1] # define output of dataset prior to function definition
def least_squares(w):
cost = 0
for p in range(0,len(y)):
cost +=(w[0] + w[1]*x[p] - y[p])**2
return cost
Note that because autograd will differentiate with respect to any input to a Python function, officially the only input here can be the weights w.
The input/output data x and y should be loaded in prior to defining the function, so that they are included in the scope of the Least Squares implementation, but treated as weights by autograd.
# test out a set of weights using our implementation of the N = 2 least squares function
w = [0,1]
least_squares(w)
To deal with arbitrary input dimension $N$ one then only needs to replace the cost update inside the for loop, i.e., cost +=(w[0] + w[1]*x[p] - y[p])**2, with the more general form.
Alternatively one can 'hard code' the gradient, writing it out algebraically and implementing the same thing in code. Using the more compact notation
\begin{equation} \widetilde{\mathbf{w}}=\left[\begin{array}{c} w_{0}\\ \mathbf{w} \end{array}\right] \,\,\,\,\text{and}\,\,\,\,\, \widetilde{\mathbf{x}}_{p}=\left[\begin{array}{c} 1\\ \mathbf{x}_{p} \end{array}\right] \end{equation}one can easily compute the general form of the gradient by hand (using the derivative rules detailed in our vital elements of calculus series) to be
\begin{equation} \nabla g\left(\widetilde{\mathbf{w}}\right) = 2\sum_{p=1}^{P} \widetilde{\mathbf{x}}_p^{\,}\left(\widetilde{\mathbf{x}}_p^T \widetilde{\mathbf{w}}_{\,}^{\,} - y_p^{\,}\right) \end{equation}In the next Python cell minimize the Least Squares cost using the toy dataset presented in Example 2.
In particular since the function is convex we use unnormalized gradient descent, and employ a fixed steplength value $\alpha = 0.01$ for all 75 steps until approximately reaching the minimum of the function.
Here we employ the file optimizers.py which contains a short list of optimization algorithms discussed in our series on mathematical optimization, including gradient descent and Newton's method.
# declare an instance of our current our optimizers
opt = superlearn.optimimzers.MyOptimizers()
# run desired algo with initial point, max number of iterations, etc.,
w_hist = opt.gradient_descent(g = least_squares,w = np.asarray([-1.0,-2.0]),max_its = 75,alpha = 10**-2)
Now we animate the process of gradient descent run above.
As you move the slider from left to right the gradient descent process animates, until completion when the slider is all the way to the right.
Simultaneously, in the left panel the corresponding linear model given by the weights at each step of gradient descent is drawn, while the point given by the weights is drawn on the Least Squares cost function contours in the right panel.
# animate descent process
demo1.animate_it_2d(w_hist,num_contours = 30)
Example 4: Using Newton's method to minimize the Least Squares cost on our toy dataset¶
In Example 6 of our post on Newton's method in our series on mathematical optimization we described how Newton's method perfectly minimizes any quadratic function in a single step. By re-writing it one can show that Least Squares cost function
with any dataset and any $N$, is always a quadratic function, hence Newton's method can be used to minimize it in a single step. Specifically, the cost function can be equivalently rewritten as
where
\begin{equation} \mathbf{A} = \sum_{p=1}^{P}\widetilde{\mathbf{x}}_{p}^{\,} \widetilde{\mathbf{x}}_{p}^T \,\,\,\,\,\,\,\,\,\,\,\,\,\mathbf{b} = -2\sum_{p=1}^{P}\widetilde{\mathbf{x}}_{p}^{\,}y_p^{\,} \,\,\,\,\,\,\,\,\,\,\,\,\, c = \sum_{p=1}^{P}y_p^2 \end{equation}We illustrate the fact that Newton's method can fit a linear regression in a single step below using the same setup as in the previous example, except Newton's method is now used instead of gradient descent. Indeed it takes only a single step to reach the minimum of the cost, while simultaneously finding a set of weights that produces a perfectly fitting line.
# declare an instance of our current our optimizers
opt = superlearn.optimimzers.MyOptimizers()
# run desired algo with initial point, max number of iterations, etc.,
w_hist = opt.newtons_method(g = least_squares,w = np.asarray([-1.0,-2.0]),max_its = 1)
# animate descent process
demo1.animate_it_2d(w_hist,num_contours = 30)
As with gradient descent, one can repeat this experiment by taking the Newton's method code provided in our series on mathematical optimization - which also uses the autograd automatic differentiator - and simply plug in the Python implementation of the Least Squares cost function given in the previous example.
Alternatively if one wishes to write out the Newton step analytically it can be shown to reduce to the following system of linear equations
\begin{equation} \left(\sum_{p=1}^{P} \widetilde{\mathbf{x}}_p^{\,}\widetilde{\mathbf{x}}_p^T \right) \widetilde{\mathbf{w}}_{\,}^{\,} = \sum_{p=1}^{P} \widetilde{\mathbf{x}}_p^{\,} y_p^{\,} \end{equation}Example 5: An example with input dimension $N=2$¶
In this example we look at another toy dataset with $N = 2$ inputs, which is plotted by the next Python cell. This dataset consists of 50 data points taken randomly from the hyperplane $y = 1 - x_1 - x_2$ with the addition of a small amount of random Gaussian noise to their $y$ value.
# load in dataset
datapath = '../../mlrefined_datasets/superlearn_datasets/3d_linregress_data.csv'
data = np.asarray(pd.read_csv(datapath,header = None))
# create instance of linear regression demo, used below and in the next examples
demo2 = superlearn.lin_regression_demos.Visualizer(data)
# plot dataset
demo2.plot_data()

To fit the Least Squares cost function we must re-define it to accept higher dimensional input. We do this in the next Python cell.
# an implementation of the least squares cost function for linear regression for N = 2 input dimension datasets
x = data[:,:-1] # define input of dataset prior to function definition
y = data[:,-1] # define output of dataset prior to function definition
def least_squares(w):
cost = 0
for p in range(0,len(y)):
x_p = x[p]
y_p = y[p]
a_p = w[0] + sum([a*b for a,b in zip(w[1:],x_p)])
cost +=(a_p - y_p)**2
return cost
In the next Python cell we minimize the Least Squares cost using the unnormalized gradient descent, a constant steplength value $\alpha = 0.001$ for 100 iterations beginning at the point
$$\begin{bmatrix} w_0 \\ w_1 \\ w_2 \end{bmatrix} = \begin{bmatrix} 1 \\ 1 \\ 1 \end{bmatrix}$$# declare an instance of our current our optimizers
opt = superlearn.optimimzers.MyOptimizers()
# run desired algo with initial point, max number of iterations, etc.,
w_hist = opt.gradient_descent(g = least_squares,w = np.asarray([1.0,1.0,1.0]),max_its = 100,alpha = 10**-3)
Now we animate this descent run. Since the linear model in this case has 3 parameters we cannot visualize each step on the contour / surface of the cost function itself, and thus must use a cost function plot (first introduced in our series on mathematical optimization) to keep visual track of the algorithm's progress.
In the left panel below we show the dataset, along with the hyperplane defined by $y = w_0 + x_1w_1 + x_2w_2$ whose weights are given at the current step in the gradient descent run.
In the right panel the corresponding cost function value which plots the evaluation of each step up to the current one.
Push the slider from left to right to animate the run from start to finish - updating corresponding hyperplane in the left panel as well as cost function value in the right at each step (both of which simultaneously colored green at the start of the run, and gradually fade to red as the run ends).
# animate descent process
demo2.animate_it_3d(w_hist,view = [10,-40],viewmax = 1.3)
1.4 The efficacy of a learned model¶
- nce we have successfully minimized the Least Squares cost the first way to measure the fit quality is the average fit to the training data
- this is called mean squared error (or MSE) and for optimal set of weights found as $w_0^{\star}$ and $\mathbf{w}^{\star}$ it is computed as
1.5 Predicting the value of new input data¶
With optimal parameters $w_0^{\star}$ and $\mathbf{w}^{\star}$ we can predict the output $y_{\textrm{new}}$ of a new input feature $\mathbf{x}_{\textrm{new}}$
- we simply plug the new input into the tuned linear model and estimating the associated output as
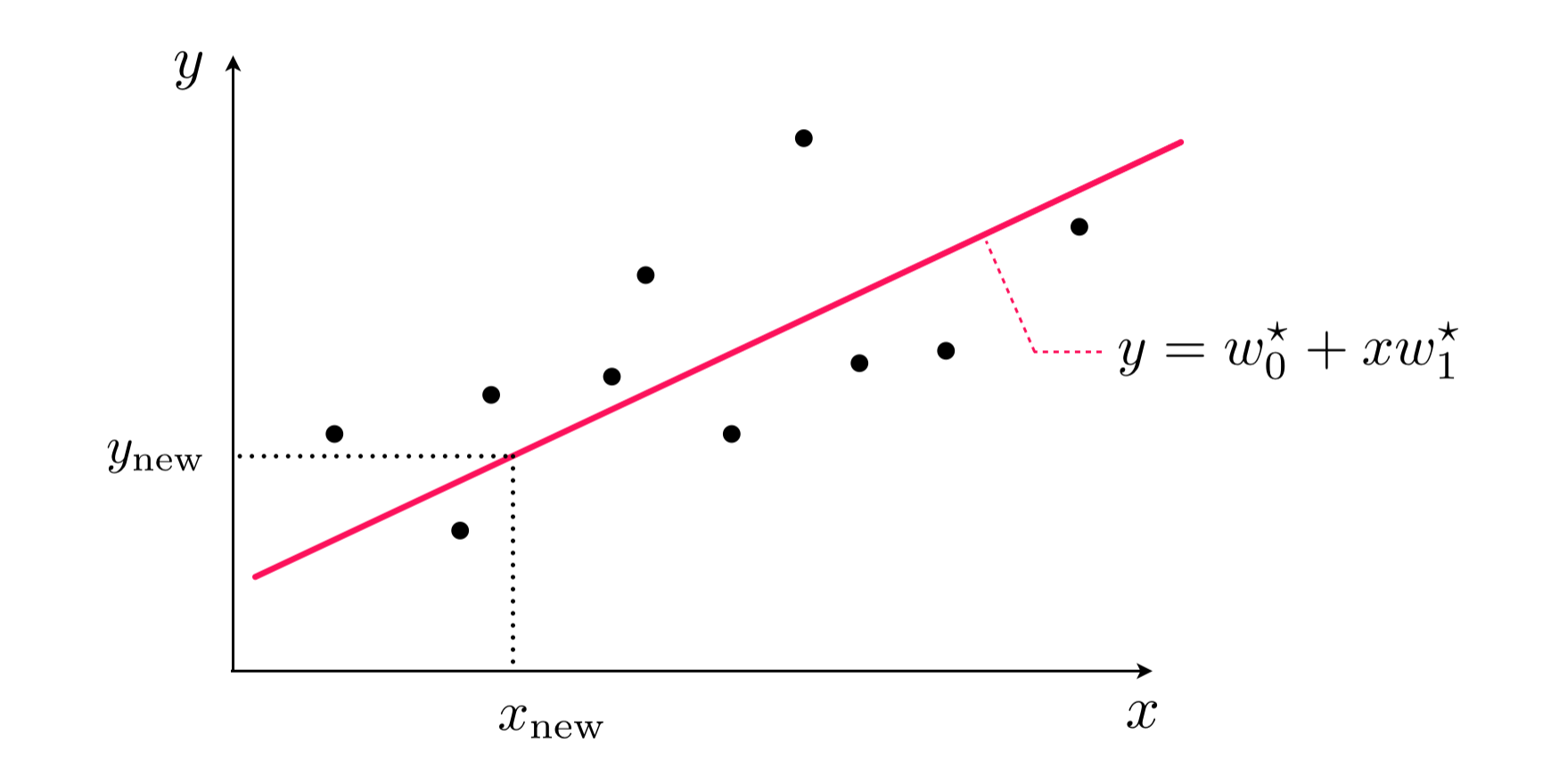
1.6 Linear regression from a probabilistic perspective¶
- we built our linear regression model on the fundamental assumption that the relationship between input and output variables is (approximately) linear, i.e., that $w_0+\mathbf{x}_{p}^T\mathbf{w} \approx y_{p}$.
- denoting the difference between $y_p$ and $w_0+\mathbf{x}_{p}^T\mathbf{w}$ as $\varepsilon_p$, we can replace these approximate equalities with exact equalities of the form
- here $\varepsilon_p$'s interpreted as error or noise in the data
With this new notation, the Least Squares cost for linear regression can be written, in terms of $\varepsilon_p$'s, as
\begin{equation} \,g\left(w_0,\mathbf{w}\right) = \sum_{p=1}^{P}\left(w_0^{\,}+\mathbf{x}_{p}^{T}\mathbf{w}^{\,}-y_{p}^{\,}\right)^{2} = \sum_{p=1}^{P} \varepsilon_p^2 \end{equation}Put into words, with linear regression we aim to find the parameters $w_0$ and $\mathbf{w}$ that minimize the total squared noise
- how do we know what the noise (random) variables should be? - we do not know typically
- assume a distribution that allows us to recover $w_0$ and $\mathbf{w}$ effectively, commonly Gaussian
- i.e., assume $\left\{ \varepsilon_p \right\} _{p=1}^{P}$ are drawn from a zero-mean Gaussian distribution
Example 6: Global sea levels are rising!¶
- below we plot both the Least Squares trend line fit to a dataset [1] consisting of satellite measurements of global mean sea level changes on earth from 1993 to 2014 (left panel), as well as the estimated noise distribution according to the learned trend line (right panel).
# load in dataset
datapath = '../../mlrefined_datasets/superlearn_datasets/climate_data.csv'
data = np.asarray(pd.read_csv(datapath,header = None))
demo1 = superlearn.regression_probabilistic_demos.visualizer(data)
# solve Least Squares
demo1.run_algo(algo='newtons_method', w_init = np.random.randn(2,1), max_its = 1)
# visualize results
demo1.error_hist(num_bins=30, xlabel='date', ylabel='sea level', show_pdf='on')

- noise of fitted line looks rather Gaussian!
Example 7: The relationship between the height of mother and the height of daughter¶
- the Francis Galton's height dataset collected in 1885 in an attempt to explore the relationship between the heights of mothers and daughters
-we plot the Least Squares linear regression fit with data in left panel, noise of fit in right panel
# load in dataset
datapath = '../../mlrefined_datasets/superlearn_datasets/mother_daughter.csv'
data = np.asarray(pd.read_csv(datapath,header = None))
demo2 = superlearn.regression_probabilistic_demos.visualizer(data)
# solve Least Squares
demo2.run_algo(algo='newtons_method', w_init = np.random.randn(2,1), max_its = 1)
# visualize results
demo2.error_hist(num_bins = 30, xlabel='height of mother', ylabel='height of daughter', show_pdf='on')

- noise looks sort of Gaussian!
- In both examples as you can see it looks like that the noise does follow a zero-mean Gaussian distribution, and hence our assumption is not far-fetched.
Statistical modeling¶
- since $\epsilon_p$ assumed Gaussian, so too is $y_p = w_0+\mathbf{x}_{p}^T\mathbf{w} +\varepsilon_p$ for all $p$, but what is mean and variance?
- in terms of data distribution we have for each point
- assuming data is independent we can form likelihood
- using the independence assumption we can write the likelihood as
- since maximizing the likelihood is mathematically equivalent to minimizing its negative log-likelihood we have the probabilistic cost function
to be minimized over $w_0$, $\mathbf{w}$, and the noise standard deviation $\sigma$.
Our first assumption on the distribution of noise makes it possible to write the exact form of $g$, with some algebra, as
\begin{equation} g\left(\widetilde{\mathbf{w}},\sigma\right)=P\,\text{log}\left(\sqrt{2\pi}\,\sigma\right)+\frac{1}{2\sigma^{2}}\sum_{p=1}^{P} \left(y_p-\widetilde{\mathbf{x}}_{p}^{T}\widetilde{\mathbf{w}}\right)^{2} \end{equation}where we have used the notation
\begin{equation} \widetilde{\mathbf{w}}=\left[\begin{array}{c} w_{0}\\ \mathbf{w} \end{array}\right] \,\,\,\,\text{and}\,\,\,\,\, \widetilde{\mathbf{x}}_{p}=\left[\begin{array}{c} 1\\ \mathbf{x}_{p} \end{array}\right] \end{equation}to write $g$ more compactly.
Checking the first order condition for optimality we have
$$ \begin{array}{c} \nabla_{\widetilde{\mathbf{w}}}g\left(\widetilde{\mathbf{w}},\sigma\right)= \frac{1}{\sigma^{2}}\sum_{p=1}^{P} \mathbf{x}_p\left(y_p-\widetilde{\mathbf{x}}_{p}^{T}\widetilde{\mathbf{w}}\right)=\mathbf{0}\\ \frac{\partial}{\partial\sigma}g\left(\widetilde{\mathbf{w}},\sigma\right)= \frac{P}{\sigma}-\frac{1}{\sigma^{3}}\sum_{p=1}^{P} \left(y_p-\widetilde{\mathbf{x}}_{p}^{T}\widetilde{\mathbf{w}}\right)^{2}=0 \end{array} $$The first equation gives the linear system
\begin{equation} \left(\sum_{p=1}^{P} \widetilde{\mathbf{x}}_p^{\,}\widetilde{\mathbf{x}}_p^T \right) \widetilde{\mathbf{w}}_{\,}^{\,} = \sum_{p=1}^{P} \widetilde{\mathbf{x}}_p^{\,} y_p^{\,} \end{equation}whose solution $\widetilde{\mathbf{w}}^\star$ can be used in the second equation to find the optimal value for the noise variance, as
\begin{equation} \sigma^2 = \frac{1}{P}\sum_{p=1}^{P} \left(y_p-\widetilde{\mathbf{x}}_{p}^{T}\widetilde{\mathbf{w}}^{\star}\right)^{2} \end{equation}Note that the linear system characterizing the fit here is identical to what we derived previously in Subsection 1.3, where interestingly enough, we found the same solution through minimizing the Least Squares cost and without making any of the statistical assumptions made here.
The maximum likelihood solution derived here using the assumptions on noise distribution and independence of data is identical to the Least Squares solution derived previously from a geometric perspective.
Even though it was necessary to assume a Gaussian distribution on the noise in order to re-derive the Least Squares solution from a probabilistic perspective, in practice we can still use Least Squares on datasets where the noise distribution is not necessarily Gaussian.
Example 8: Least Squares and uniformly distributed noise¶
- below in left panel we create a simulated dataset with uniformly distributed noise and fit a Least Squares line to it as we did previously in Examples 6 and 7
- the Least Squares solution (left panel) still provides a good fit to the data even though the assumption of Gaussian distribution on noise is not met (right panel)
# make and load a simulated dataset with uniformly distributed noise
num_pts = 200
x = np.random.rand(num_pts)
y = 4*x + np.random.rand(num_pts)
x.shape = (len(x),1)
y.shape = (len(y),1)
data = np.concatenate((x,y),axis = 1)
demo3 = superlearn.regression_probabilistic_demos.visualizer(data)
# solve Least Squares
demo3.run_algo(algo='newtons_method', w_init = np.random.randn(2,1), max_its = 1)
# visualize results
demo3.error_hist(num_bins = 30)

- this is now an unrealistic dataset, in practice we do not know what the noise distribution really is